ERDDAP™
is a web application and a web service that aggregates scientific data from
diverse local and
remote sources and offers a simple, consistent way to download subsets of the
data in common file
formats and make graphs and maps.
This web page discusses issues related to heavy ERDDAP™ usage loads
and explores possibilities for dealing with extremely heavy loads
via grids, clusters, federations, and cloud computing.
The original version was written in June 2009. There have been no significant
changes. This was last updated 2019-04-15.
Table of Contents
The contents of this web page are Bob Simons personal opinions and
do not necessarily reflect any position of the
Government or the National Oceanic and Atmospheric Administration.
The calculations are simplistic, but I think the conclusions are correct.
Did I use faulty logic or make a mistake in my calculations?
If so, the fault is mine alone.
Please send an email with the correction to
erd dot data at noaa dot gov.
With heavy use, a standalone ERDDAP™ will be constrained (from most to least likely) by:
- A remote data source's bandwidth —
Even with an efficient connection (e.g., via OPeNDAP),
unless a remote data source has a very high bandwidth
Internet connection, ERDDAP's responses will be constrained by how fast ERDDAP™ can get
data from the data source. A solution is to copy the dataset onto ERDDAP's hard drive,
perhaps with
EDDGridCopy
or
EDDTableCopy.
- ERDDAP's server's bandwidth — Unless ERDDAP's server has a very high bandwidth Internet
connection, ERDDAP's responses will be constrained by how fast ERDDAP™ can get data from
the data sources and how fast ERDDAP™ can return data to the clients. The only solution
is to get a faster Internet connection.
- Memory —
If there are many simultaneous requests, ERDDAP™ can run out of memory
and temporarily refuse new requests.
(ERDDAP™ has a couple of mechanisms to avoid this and to minimize the
consequences if it does
happen.) So the more memory in the server the better.
On a 32-bit server, 4+ GB is really good, 2 GB is okay,
less is not recommended.
On a 64-bit server, you can almost entirely avoid the problem by getting
lots of memory.
See the
-Xmx and -Xms settings
for ERDDAP/Tomcat.
An ERDDAP™ getting heavy usage on a computer with a 64-bit server
with 8GB of memory and -Xmx set to 4000M is rarely, if ever, constrained by memory.
- Hard drive bandwidth —
Accessing data stored on the server's hard drive
is vastly faster than
accessing remote data. Even so, if the ERDDAP™ server has a very high
bandwidth Internet connection,
it is possible that accessing data on the hard drive will be a bottleneck.
A partial solution
is to use faster (e.g., 10,000 RPM) magnetic hard drives
or SSD drives (if it makes
sense cost-wise). Another solution is to store different datasets
on different drives, so that the cumulative hard drive bandwidth is much higher.
- Too many files
in a cache directory —
ERDDAP™ caches all images, but only caches the
data for certain types of data requests. It is possible for the cache directory for a
dataset to have a large number of files temporarily. This will slow down requests to see
if a file is in the cache (really!). <cacheMinutes> in
setup.xml
lets you set how
long a file can be in the cache before it is deleted. Setting a smaller
number would minimize this problem.
- CPU —
Only two things take a lot of CPU time:
- NetCDF 4 and HDF 5 now support internal compression of data.
Decompressing a large compressed NetCDF 4 / HDF 5 data file can take 10
or more seconds. (That's not an implementation fault. It's the nature of compression.)
So, multiple simultaneous requests to datasets with
data stored in compressed files can put a severe strain on any server.
If this is a problem, the solution is to store popular datasets
in uncompressed files, or get a server with a CPU with more cores.
- Making graphs (including maps): roughly 0.2 - 1 second per graph.
So if there were many simultaneous unique requests for graphs
(WMS clients often make 6 simultaneous requests!),
there could be a CPU limitation.
When multiple users are running WMS clients, this becomes a problem.
The question often comes up:
"To deal with heavy loads, can I set up multiple identical ERDDAPs with load balancing?"
It's an interesting question because it quickly gets to the core of ERDDAP's design.
The quick answer is "no".
I know that is a disappointing answer,
but there are a couple of direct reasons and some larger fundamental reasons
why I designed ERDDAP™ to use a different approach
(a federation of ERDDAPs, described in the bulk of this document),
which I believe is a better solution.
Some direct reasons why you can't/shouldn't set up multiple identical ERDDAPs are:
- A given ERDDAP™ reads each data file when it first becomes available
in order to find the ranges of data in the file. It then stores
that information in an index file.
Later, when a user request for data comes in,
ERDDAP™ uses that index to figure out which files to look in for the requested data.
If there were multiple identical ERDDAPs, they would each be doing
this indexing, which is wasted effort.
With the federated system described below, the indexing is only done once, by one of the ERDDAPs.
- For some types of user requests (e.g., for .nc, .png, .pdf files)
ERDDAP™ has to make the entire file before the response can be sent.
So ERDDAP™ caches these files for a short time. If an identical request
comes in (as it often does, especially for images where the URL is embedded in a web page),
ERDDAP™ can reuse that cached file.
In a system of multiple identical ERDDAPs, those cached files are not shared,
so each ERDDAP™ would needlessly and wastefully recreate the .nc, .png, or .pdf files.
With the federated system described below, the files are only made once, by one of the ERDDAPs, and reused.
- ERDDAP's subscription system is not set up to be shared by multiple ERDDAPs.
For example, if the load balancer sends a user to one ERDDAP™ and the user subscribes to a dataset,
then the other ERDDAPs won't be aware of that subscription. Later,
if the load balancer sends the user to a different ERDDAP™ and asks for
a list of his/her subscriptions, the other ERDDAP™ will say there are none
(leading him/her to make a duplicate subscription on the other EREDDAP).
With the federated system described below, the subscription system is
simply handled by the main, public, composite ERDDAP.
Yes, for each of those problems, I could (with great effort) engineer a solution
(to share the information between ERDDAPs), but I think the
federation-of-ERDDAPs approach
(described in the bulk of this document) is a much better overall solution,
partly because it deals with other problems
that the multiple-identical-ERDDAPs-with-a-load-balancer approach does not even start to address,
notably the decentralized nature of the data sources in the world.
It's best to accept the simple fact that I didn't design ERDDAP™ to be deployed as
multiple identical ERDDAPs with a load balancer. I consciously designed ERDDAP™
to work well within a federation of ERDDAPs, which I believe has many advantages.
Notably, a federation of ERDDAPs is perfectly aligned with the decentralized, distributed system of
data centers that we have in the real world (think of the different IOOS regions,
or the different CoastWatch regions, or the different parts of NCEI,
or the 100 other data centers in NOAA, or the different NASA DAACs,
or the 1000's of data centers throughout the world).
Instead of telling all the data centers
of the world that they need to abandon their efforts and put all their data
in a centralized "data lake" (even if it were possible, it is a horrible idea for numerous reasons
-- see the various analyses showing the numerous advantages of
decentralized systems ),
ERDDAP's design works with the world as it is.
Each data center which produces data can continue to maintain, curate, and serve their data (as they should),
and yet, with ERDDAP™, the data can also be instantly available from a centralized ERDDAP,
without the need for transmitting the data to the centralized ERDDAP™ or
storing duplicate copies of the data.
Indeed, a given dataset can be simultaneously available
),
ERDDAP's design works with the world as it is.
Each data center which produces data can continue to maintain, curate, and serve their data (as they should),
and yet, with ERDDAP™, the data can also be instantly available from a centralized ERDDAP,
without the need for transmitting the data to the centralized ERDDAP™ or
storing duplicate copies of the data.
Indeed, a given dataset can be simultaneously available
from an ERDDAP™ at the organization that produced and actually stores the data (e.g., GoMOOS),
from an ERDDAP™ at the parent organization
(e.g., IOOS central),
from an all-NOAA ERDDAP™,
from an all-US-federal government ERDDAP™,
from a global ERDDAP™ (GOOS),
and from specialized ERDDAPs (e.g.,
an ERDDAP™ at an institution devoted to HAB research),
all essentially instantaneously,
and efficiently because only the metadata is transferred between ERDDAPs, not the data.
Best of all, after the initial ERDDAP™ at the originating organization, all of the
other ERDDAPs can be set up quickly (a few hours work), with minimal resources
(one server that doesn't need any RAIDs for data storage since it stores no data locally),
and thus at truly minimal cost.
Compare that to the cost of setting up and maintaining a centralized data center with a data lake
and the need for a truly massive, truly expensive, Internet connection),
plus the attendant problem of the centralized data center being a single point of failure.
To me, ERDDAPs decentralized, federated approach is far, far superior.
In situations where a given data center needs multiple ERDDAPs to meet
high demand, ERDDAP's design is fully capable of matching or exceeding the performance
of the multiple-identical-ERDDAPs-with-a-load-balancer approach.
You always have the option of setting up
multiple composite ERDDAPs (as discussed below),
each of which gets all of their data from other ERDDAPs, without load balancing.
In this case, I recommend that you make a point of giving each of the composite
ERDDAPs a different name / identity
and if possible setting them up in different parts of the world
(e.g., different AWS regions),
e.g., ERD_US_East, ERD_US_West, ERD_IE, ERD_FR, ERD_IT,
so that users consciously, repeatedly, work with a specific ERDDAP,
with the added benefit that you have removed the risk from a single point of failure.
Under very heavy use, a single standalone ERDDAP™ will run into one or more of the
constraints listed
above and even the suggested solutions will be insufficient. For such situations,
ERDDAP™ has
features that make it easy to construct scalable grids (also called clusters or federations)
of ERDDAPs which allow the system to handle very heavy use (e.g., for a large data center).
I'm using
grid
as a general term to indicate a type of
computer cluster
where all of the
parts may or may not be physically located in one facility and may or may not be centrally
administered. An advantage of co-located, centrally owned and administered grids (clusters)
is that they benefit from economies of scale (especially the human workload) and simplify
making the parts of the system work well together. An advantage of non-co-located grids,
non-centrally owned and administered (federations)
is that they distribute the human workload
and the cost, and may provide some additional fault tolerance.
The solution I propose below works well for all grid, cluster, and federation topographies.
The basic idea of designing a scalable system is to identify the potential bottlenecks
and then design the system so that parts of the system can be replicated as needed to
alleviate the bottlenecks. Ideally, each replicated part increases the capacity of that
part of the system linearly (efficiency of scaling). The system isn't scalable unless
there is a scalable solution for every bottleneck.
Scalability
is different from efficiency (how quickly a task can be done — efficiency
of the parts). Scalability allows the system to grow to handle any level of demand.
Efficiency (of scaling and of the parts) determines how many servers, etc., will be needed
to meet a given level of demand. Efficiency is very important, but always has limits.
Scalability is the only practical solution to building a system that can handle very
heavy use. Ideally, the system will be scalable and efficient.
The goals of this design are:
- To make a scalable architecture
(one that is easily extensible by replicating any part that
becomes over-burdened). To make an efficient system that maximizes the
availability and
throughput of the data given the available computing resources.
(Cost is almost always an issue.)
- To balance the capabilities of the parts of the system so that one part
of the system won't overwhelm another part.
- To make a simple architecture so that the system is easy to set up and administer.
- To make an architecture that works well with all grid topographies.
- To make a system that fails gracefully
and in a limited way if any part becomes over-burdened.
(The time required to copy a large datasets will always limit
the system's ability to deal
with sudden increases in the demand for a specific dataset.)
- (If possible) To make an architecture that isn't tied to any specific
cloud computing service
or other external services (because it doesn't need them).
Our recommendations are:
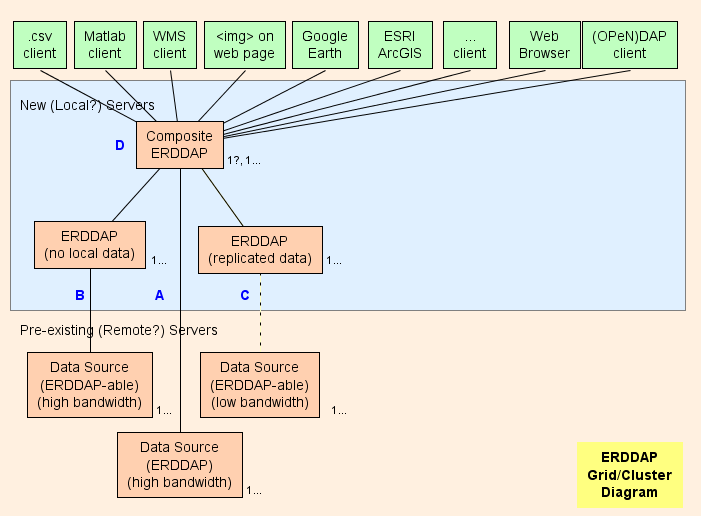
- Basically, I suggest setting up a Composite ERDDAP™
(D in the diagram), which is a
regular ERDDAP™ except that it just serves data from other ERDDAPs.
The grid's architecture
is designed to shift as much work as possible
(CPU usage, memory usage, bandwidth usage)
from the Composite ERDDAP™ to the other ERDDAPs.
- ERDDAP™ has two special dataset types,
EDDGridFromErddap
and
EDDTableFromErddap,
which refer to
datasets on other ERDDAPs.
- When the composite ERDDAP™ receives a request for data or images from
these datasets, the composite ERDDAP™
redirects
the data request to the other ERDDAP™ server. The result is:
- This is very efficient (CPU, memory, and bandwidth), because otherwise
- The composite ERDDAP™ has to send the data request to the other ERDDAP.
- The other ERDDAP™ has to get the data, reformat it,
and transmit the data to the composite ERDDAP.
- The composite ERDDAP™ has to receive the data (using extra bandwidth),
reformat it (using extra CPU time and memory),
and transmit the data to the user (using extra bandwidth).
By redirecting the data request and allowing the other ERDDAP™ to send the
response directly
to the user, the composite ERDDAP™ spends essentially no CPU time, memory,
or bandwidth on data requests.
- The redirect is transparent to the user regardless of the client software
(a browser or any other software or command line tool).
The parts of the grid are:
A) For every remote data source that
has a high-bandwidth OPeNDAP server, you can connect directly
to the remote server.
If the remote server is an ERDDAP™, use EDDGridFromErddap or
EDDTableFromERDDAP to serve the data in the Composite ERDDAP.
If the remote server is some other type of DAP server,
e.g., THREDDS, Hyrax, or GrADS, use EDDGridFromDap.
B) For every ERDDAP-able data source
(a data source from which ERDDAP
can read data) that has a high-bandwidth server, set up another ERDDAP™ in
the grid which
is responsible for serving the data from this data source.
- If several such ERDDAPs aren't getting many requests for data, you can
consolidate them into one ERDDAP.
- If the ERDDAP™ dedicated to getting data from one remote source is
getting too many requests,
there is a temptation to add additional ERDDAPs to access the remote
data source. In special cases this may make sense,
but it is more likely that this will overwhelm the remote data
source (which is self-defeating) and also prevent other users
from accessing the remote data source (which isn't nice).
In such a case, consider setting up another ERDDAP™ to serve that
one dataset and copy the dataset on that ERDDAP's hard drive (see C),
perhaps with
EDDGridCopy
and/or
EDDTableCopy.
- B servers must be publicly accessible.
C) For every ERDDAP-able data source
that has a low-bandwidth server
(or is a slow service for other reasons),
consider setting up another ERDDAP™ and storing a copy of the dataset
on that ERDDAP's hard drives, perhaps with
EDDGridCopy
and/or
EDDTableCopy.
If several such ERDDAPs
aren't getting many requests for data, you can consolidate them into one ERDDAP.
C servers must be publicly accessible.
D)
The composite ERDDAP™ is a regular
ERDDAP™ except that it just serves data from other ERDDAPs.
- Because the composite ERDDAP™ has information in memory about all of the
datasets, it can
quickly respond to requests for lists of datasets (full text searches, category searches,
the list of all datasets), and requests for an individual dataset's Data Access Form,
Make A Graph form, or WMS info page. These are all small, dynamically generated, HTML
pages based on information which is held in memory. So the responses are very fast.
- Because requests for actual data are quickly redirected to the other ERDDAPs,
the composite
ERDDAP™ can quickly respond to requests for actual data without using any CPU time, memory, or bandwidth.
- By shifting as much work as possible (CPU, memory, bandwidth)
from the Composite ERDDAP™ to
the other ERDDAPs, the composite ERDDAP™ can appear to serve data
from all of the datasets
and yet still keep up with very large numbers of data requests
from a large number of users.
- Preliminary tests indicate that the composite ERDDAP™ can respond to
most requests in ~1ms of
CPU time, or 1000 requests/second. So an 8 core processor should be able
to respond to about 8000 requests/second.
Although it is possible to envision bursts of higher activity
which would cause slowdowns, that is a lot of throughput.
It is likely that data center
bandwidth will be the bottleneck long before the composite ERDDAP™ becomes the bottleneck.
- Up-to-date max(time)?
The EDDGrid/TableFromErddap in the composite ERDDAP™ only changes its
stored information about each source dataset
when the source dataset is
"reload"ed
and some piece of metadata changes (e.g.,
the time variable's actual_range), thereby generating a subscription notification.
If the source dataset has data that changes frequently (for example, new data every second)
and uses the
"update"
system to notice frequent changes to the underlying data,
the EDDGrid/TableFromErddap won't be notified about these frequent changes
until the next dataset "reload",
so the EDDGrid/TableFromErddap won't be perfectly up-to-date.
You can minimize this problem by changing the
source dataset's <reloadEveryNMinutes> to a smaller value
(60? 15?) so that there are more subscription notifications to tell
the EDDGrid/TableFromErddap to update its information about the source dataset.
Or, if your data management system knows when the source dataset has new data
(e.g., via a script that copies a data file into place), and if that isn't
super frequent (e.g., every 5 minutes, or less frequent), there's a better solution:
- Don't use <updateEveryNMillis> to keep the source dataset up-to-date.
- Set the source dataset's <reloadEveryNMinutes> to a larger number (1440?).
- Have the script contact the source dataset's
flag URL
right after it copies a new data file into place.
That will lead to the source dataset being perfectly up-to-date
and cause it to generate a subscription notification,
which will be sent to the EDDGrid/TableFromErddap dataset.
That will lead the EDDGrid/TableFromErddap dataset to be perfectly up-to-date
(well, within 5 seconds of new data being added).
And all that will be done efficiently (without unnecessary dataset reloads).
- In very extreme cases, or for fault tolerance,
you may want to set up more than one composite ERDDAP.
It is likely that other parts of the system (notably, the data center's bandwidth)
will become a problem long before the composite ERDDAP™ becomes a bottleneck.
So the solution is probably to set up additional, geographically diverse, data centers
(mirrors), each with one composite ERDDAP™ and servers with ERDDAPs and (at least) mirror
copies of the datasets which are in high demand. Such a setup also provides fault
tolerance and data backup (via copying).
In this case, it is best if the composite ERDDAPs have different URLs.
If you really want all of the composite ERDDAPs to have the same URL,
use a front end system
that assigns a given user to just one of the composite ERDDAPs (based on the IP address),
so that all of the user's requests go to just one of the composite ERDDAPs.
There are two reasons:
- When an underlying dataset is reloaded and the metadata changes
(e.g., a new data file in a gridded dataset causes the time variable's
actual_range to change),
the composite ERDDAPs will be temporarily slightly out of synch, but with
eventual consistency.
Normally, they will re-synch within 5 seconds, but sometimes it will be longer.
If a user makes an automated system that relies on
ERDDAP™ subscriptions that trigger actions, the brief synchronicity
problems will become significant.
- The 2+ composite ERDDAPs each maintain their own set of subscriptions
(because of the synch problem described above).
So a given user should be directed to just one of the composite ERDDAPs
to avoid these problems.
If one of the composite ERDDAPs goes down, the front end system can
redirect that ERDDAP's users to another ERDDAP™ that is up.
However, if it is a capacity problem that causes the first composite ERDDAP™ to fail
(an overzealous user? a
denial-of-service attack?),
this makes it very likely that redirecting its users to other composite ERDDAPs
will cause a
cascading failure.
Thus, the most robust setup is to have composite ERDDAPs with different URLs.
Or, perhaps better, set up multiple composite ERDDAPs without load balancing.
In this case, you should make a point of giving each of the ERDDAPs a different
name / identity and if possible setting them up in different parts of the world
(e.g., different AWS regions),
e.g., ERD_US_East, ERD_US_West, ERD_IE, ERD_FR, ERD_IT,
so that users consciously, repeatedly work with a specific ERDDAP.
- [For a fascinating design of a high performance system running on one server,
see this detailed description of Mailinator.]
Datasets In Very High Demand —
In the really unusual case that one of the
A, B, or C ERDDAPs
can't keep up with the requests because of bandwidth or hard drive limitations,
it makes sense to copy the data (again) on to another server+hardDrive+ERDDAP,
perhaps with
EDDGridCopy
and/or
EDDTableCopy.
While it may seem ideal to have the original dataset and the
copied dataset appear seamlessly as one dataset in the composite ERDDAP™, this is difficult
because the two datasets will be in slightly different states at different times (notably,
after the original gets new data, but before the copied dataset gets its copy).
Therefore, I recommend that the datasets be given slightly different titles (e.g.,
"... (copy #1)" and "... (copy #2)", or perhaps "(mirror #n)" or "(server #n)") and
appear as separate datasets in the composite ERDDAP.
Users are used to seeing lists of
mirror sites
at popular file download sites, so this shouldn't surprise or disappoint them.
Because of bandwidth limitations at a given site, it may make sense to have the mirror
located at another site. If the mirror copy is at a different data center, accessed just
by that data center's composite ERDDAP™, the different titles (e.g., "mirror #1) aren't
necessary.
RAIDs versus Regular Hard Drives —
If a large dataset or a group of datasets are not heavily used,
it may make sense to store the data on a RAID since it offers fault tolerance and since
you don't need the processing power or bandwidth of another server. But if a dataset is
heavily used, it may make more sense to copy the data on another server + ERDDAP™ + hard
drive (similar to
what Google does)
rather than to use one server and a RAID to store
multiple datasets since you get to use both server+hardDrive+ERDDAPs in the grid until
one of them fails.
Failures — What happens if...
- There is a burst of requests for one dataset (e.g., all students in a class
simultaneously request similar data)?
Only the ERDDAP™ serving that dataset will be overwhelmed and
slow down or refuse requests. The composite ERDDAP™ and other ERDDAPs won't be
affected. Since the limiting factor for a given dataset within the system is the hard
drive with the data (not ERDDAP), the only solution (not immediate) is to make a copy
of the dataset on a different server+hardDrive+ERDDAP.
- An A, B, or C ERDDAP™ fails (e.g., hard drive failure)?
Only the dataset(s) served by that ERDDAP™ are affected.
If the dataset(s) is mirrored on another server+hardDrive+ERDDAP, the effect is minimal.
If the problem is a hard drive failure in a level 5 or 6 RAID, you just replace the
drive and have the RAID rebuild the data on the drive.
- The composite ERDDAP™ fails?
If you want to make a system with very
high availability,
you can set up
multiple composite ERDDAPs (as discussed above),
using something like
NGINX
or
Traefik
to handle load balancing.
Note that a given composite ERDDAP™ can handle a very large number of requests
from a large number of users because
requests for metadata are small and are handled by information that is in memory,
and
requests for data (which may be large) are redirected to the child ERDDAPs.
Simple,
Scalable
— This system is easy to set up and administer,
and easily extensible when
any part of it becomes over-burdened. The only real limitations for a given data center
are the data center's bandwidth and the cost of the system.
Bandwidth —
Note the approximate bandwidth of commonly used components of the system:
| Component | Approximate Bandwidth (GBytes/s) |
|---|
| DDR memory | 2.5 |
| SSD drive | 1 |
| SATA hard drive | 0.3 |
| Gigabit Ethernet | 0.1 |
| OC-12 | 0.06 |
| OC-3 | 0.015 |
| T1 | 0.0002 |
So, one SATA hard drive (0.3GB/s) on one server with one ERDDAP™ can probably saturate a
Gigabit Ethernet LAN (0.1GB/s).
And one Gigabit Ethernet LAN (0.1GB/s) can probably saturate an OC-12 Internet connection
(0.06GB/s).
And at least one source lists OC-12 lines costing about $100,000 per month.
(Yes, these calculations are based on pushing the system to its limits,
which is not good because it leads to very sluggish responses.
But these calculations are useful for planning and for balancing parts of the system.)
Clearly, a suitably fast Internet connection for your data center is
by far the most expensive part of the system.
You can easily and relatively cheaply build a grid with a dozen servers
running a dozen ERDDAPs
which is capable of pumping out lots of data quickly,
but a suitably fast Internet connection will be very, very expensive.
The partial solutions are:
- Encourage clients to request subsets of the data if that is all that is needed.
If the client only needs data for a small region or at a lower resolution,
that is what they should request.
Subsetting is a central focus of the protocols ERDDAP™ supports for
requesting data.
- Encourage transmitting compressed data.
ERDDAP™ compresses
a data transmission if it
finds "accept-encoding" in the HTTP GET request header. All web browsers use
"accept-encoding" and automatically decompress the response. Other clients
(e.g., computer programs) have to use it explicitly.
- Colocate your servers at an ISP or other site that offers relatively
less expensive bandwidth costs.
- Disperse the servers with the ERDDAPs to different institutions so that
the costs are dispersed.
You can then link your composite ERDDAP™ to their ERDDAPs.
Note that
Cloud Computing and web hosting services
offer all the Internet bandwidth
you need, but don't solve the price problem.
For general information on designing scalable,
high capacity, fault-tolerant systems,
see Michael T. Nygard's book
Release It.
Like Legos
— Software designers often try to use good
software design patterns
to solve problems. Good patterns are good because they encapsulate good,
easy to create and work with, general-purpose solutions that lead to systems
with good properties. Pattern names are not standardized, so I'll call
the pattern that ERDDAP™ uses
the Lego Pattern. Each Lego (each ERDDAP) is a simple, small,
standard, stand-alone, brick (data server) with a defined interface
that allows it to be linked to other legos (ERDDAPs).
The parts of ERDDAP™ that make up this system are:
the subscription and flagURL systems (which allows for
communication between ERDDAPs), the EDD...FromErddap redirect system,
and the system of RESTful requests for data which can be generated
by users or other ERDDAPs.
Thus, given two or more legos (ERDDAPs),
you can create a huge number of different shapes (network topologies of ERDDAPs).
Sure, the design and features of ERDDAP™ could have been done differently,
not Lego-like, perhaps just to enable and optimize for one specific topology.
But we feel that ERDDAP's Lego-like design offers a good,
general-purpose solution that enables any ERDDAP™ administrator
(or group of administrators)
to create all kinds of different federation topologies. For example, a
single organization could set up three (or more) ERDDAPs
as shown in the
ERDDAP™ Grid/Cluster Diagram above.
Or a distributed group
(IOOS? CoastWatch? NCEI? NWS? NOAA? USGS? DataONE? NEON? LTER? OOI? BODC? ONC? JRC? WMO?)
can set up one ERDDAP™
in each small outpost (so the data can stay close to the source)
and then set up a composite ERDDAP™ in the
central office with virtual datasets (which are always perfectly up-to-date)
from each of the small outpost ERDDAPs.
Indeed, all of the ERDDAPs, installed at various institutions around
the world, which get data from other ERDDAPs and/or provide data to
other ERDDAPs, form a giant network of ERDDAPs. How cool is that?!
So, as with Lego's, the possibilities are endless. That's why this is a
good pattern. That's why this is a good design for ERDDAP.
Different Types Of Requests
— One of the real-life complications of this discussion of data server topologies
is that there are different types of requests and
different ways to optimize for the different types of requests.
This is mostly a separate issue
(How fast can the ERDDAP™ with the data respond to the request for data?)
from the topology discussion (which deals with the relationships between data servers
and which server has the actual data).
ERDDAP™, of course, tries to deal with all types of requests efficiently,
but handles some better than others.
- Many requests are simple.
For example: What is the metadata for this dataset?
Or: What are the values of the time dimension for this gridded dataset?
ERDDAP™ is designed to handle
these as quickly as possible (usually in <=2 ms) by keeping this information in memory.
- Some requests are moderately hard.
For example: Give me this subset of a dataset
(which is in one data file). These requests can be handled relatively quickly
because they aren't that difficult.
- Some requests are hard and thus are time consuming.
For example: Give me this subset of a dataset (which might be in any of the 10,000+
data files, or might be from compressed data files that each take 10 seconds to decompress).
ERDDAP™ v2.0 introduced some new, faster ways to deal with these requests, notably by
allowing the request-handling thread to spawn several worker threads
which tackle different subsets of the request. But there is another approach
to this problem which ERDDAP™ does not yet support: subsets of the data files
for a given dataset could be stored
and analyzed on separate computers, and then the results combined on the
original server. This approach is called
MapReduce
and is exemplified by
Hadoop,
the first (?) open-source MapReduce program,
which was based on ideas from a Google paper. (If you need MapReduce in ERDDAP,
please send an email request to erd.data at noaa.gov.)
Google's
BigQuery
is interesting because it seems to be an implementation of MapReduce applied
to subsetting tabular datasets, which is one of ERDDAP's main goals.
It is likely that you can create an ERDDAP™ dataset from a BigQuery dataset via
EDDTableFromDatabase
because BigQuery can be accessed via a JDBC interface.
Yes, the calculations are simplistic (and now slightly dated), but I think the conclusions are correct.
Did I use faulty logic or make a mistake in my calculations? If so, the fault is mine alone.
Please send an email with the correction to erd dot data at noaa dot gov.
Several companies offer cloud computing services
(e.g.,
Amazon Web Services
and
Google Cloud Platform).
Web hosting companies
have offered simpler services since the mid-1990's,
but the "cloud" services have greatly expanded the flexibility
of the systems and the range of services offered.
Since the ERDDAP™ grid just consists of ERDDAPs and
since ERDDAPs are Java web applications that can run in Tomcat (the most common
application server) or other application servers, it should be relatively easy to
set up an ERDDAP™ grid on a cloud service or web hosting site.
The advantages of these services are:
- They offer access to very high bandwidth Internet connections.
This alone may justify using these services.
- They only charge for the services you use.
For example, you get access to a very high
bandwidth Internet connection, but you only pay for actual data transferred.
That lets you build a system that rarely gets overwhelmed (even at peak demand),
without having to pay for capacity that is rarely used.
- They are easily extensible. You can change server types or add
as many servers or as much storage as you want, in less than a minute.
This alone may justify using these services.
- They free you from many of the administrative duties of running the
servers and networks.
This alone may justify using these services.
The disadvantages of these services are:
- They charge for their services, sometimes a lot
(in absolute terms; not that it isn't a good value).
The prices listed here are for
Amazon EC2.
These prices (as of June 2015) will come down.
In the past, prices were higher,
but data files and the number of requests were smaller.
In the future, prices will be lower,
but data files and the number of requests will be larger.
So the details change, but the situation stays relatively constant.
And it isn't that the service is overpriced,
it is that we are using and buying a lot of the service.
- Data Transfer — Data transfers into the system are now free (Yea!).
Data transfers out of the system are $0.09/GB.
One SATA hard drive (0.3GB/s) on one server with one ERDDAP™ can probably
saturate a Gigabit Ethernet LAN (0.1GB/s).
One Gigabit Ethernet LAN (0.1GB/s) can probably saturate an OC-12 Internet
connection (0.06GB/s).
If one OC-12 connection can transmit ~150,000 GB/month, the Data Transfer costs
could be as much as 150,000 GB @ $0.09/GB = $13,500/month,
which is a significant cost.
Clearly, if you have a dozen hard-working ERDDAPs on a cloud service, your
monthly Data Transfer fees could be substantial (up to $162,000/month).
(Again, it isn't that the service is overpriced,
it is that we are using and buying a lot of the service.)
- Data storage — Amazon charges $50/month per TB.
(Compare that to buying a 4TB enterprise drive outright for ~$50/TB,
although the RAID to put it in and administrative costs add to the total cost.)
So if you need to store lots of data in the cloud,
it might be fairly expensive (e.g., 100TB would cost $5000/month).
But unless you have a really large amount of data,
this is a smaller issue than the bandwidth/data transfer costs.
(Again, it isn't that the service is overpriced,
it is that we are using and buying a lot of the service.)
- The subsetting problem:
The only way to efficiently distribute data from data files
is to have the program which is distributing the data (e.g., ERDDAP) running on
a server which has the data stored on a local hard drive
(or similarly fast access to a SAN or local RAID).
Local file systems allow ERDDAP™ (and underlying libraries, such as netcdf-java)
to request specific byte ranges from the files and get responses very quickly.
Many types of data requests from ERDDAP™ to the file
(notably gridded data requests where the stride value
is > 1) can't be done efficiently if the program
has to request the entire file or big chunks of a file
from a non-local (hence slower) data storage system and then extract a subset.
If the cloud setup doesn't give ERDDAP™ fast access to byte ranges of the files
(as fast as with local files),
ERDDAP's access to the data will be a severe bottleneck
and negate other benefits of using a cloud service.
Hosted Data -
An alternative to the above cost benefit analysis
(which is based on the data owner (e.g., NOAA)
paying for their data to be stored in the cloud)
arrived around 2012, when Amazon
(and to a lesser extent, some other cloud providers)
started hosting some datasets in their cloud (AWS S3) for free
(presumably with the hope that
they could recover their costs
if users would rent AWS EC2 compute instances to work with that data).
Clearly, this makes cloud computing vastly more cost effective,
because the time and cost up uploading the data and hosting it are now zero.
With ERDDAP™ v2.0, there are new features to facilitate running ERDDAP
in a cloud:
- Now, a EDDGridFromFiles or EDDTableFromFiles dataset can be
created from data files which are remote and accessible via the internet
(e.g., AWS S3 buckets) by using the <cacheFromUrl> and
<cacheSizeGB> options.
ERDDAP™ will maintain a local cache of the most recently used data files.
- Now, if any EDDTableFromFiles source files are compressed (e.g., .tgz),
ERDDAP™ will automatically decompress them when it reads them.
- Now, the ERDDAP™ thread responding to a given request will spawn worker threads
to work on subsections of the request if you use the
<nThreads> options. This parallelization should
allow faster responses to difficult requests.
These changes solve the problem of AWS S3 not offering local, block-level
file storage and the (old) problem of access to S3 data having a significant lag.
(Years ago (~2014), that lag was significant, but is now much shorter and so not as significant.)
All in all, it means that setting up ERDDAP™ in the cloud works much better now.
Thanks —
Many thanks to Matthew Arrott and his group in the original OOI effort
for their work on putting ERDDAP™ in
the cloud and the resulting discussions.
There is a common problem that is related to the above discussion of grids and federations of ERDDAPs:
remote replication of datasets.
The basic problem is: a data provider maintains a dataset that changes occasionally
and a user wants to maintain an up-to-date local copy of this dataset (for any of
a variety of reasons). Clearly, there are a huge number of variations of this.
Some variations are much harder to deal with than others.
- Fast Updates
It's harder to keep the local dataset up-to-date immediately (e.g., within 3 seconds)
after every change to the source, rather than, for example, within a few hours.
- Frequent Changes
Frequent changes are harder to deal with than infrequent changes.
For example, once-a-day changes are
much easier to deal with than changes every 0.1 second.
- Small Changes
Small changes to a source file are harder to deal with than an entirely new file.
This is especially true if the small changes may be anywhere in the file.
Small changes are harder to detect and make it hard to isolate the data that needs to be replicated.
New files are easy to detect and efficient to transfer.
- Entire Dataset
Keeping an entire dataset up-to-date is harder than maintaining just recent data.
Some users just need recent data (e.g., the last 8 day's worth).
- Multiple Copies
Maintaining multiple remote copies at different sites is harder than maintaining one remote copy.
This is the scaling problem.
There are obviously a huge number of variations of possible types of changes to
the source dataset and of the user's needs and expectations. Many of the variations are
very difficult to solve. The best solution for one situation is often not the
best solution for another situation — there isn't yet a universal great solution.
ERDDAP™ offers several tools which can be used as part of a system which
seeks to maintain a remote copy of a dataset:
- ERDDAP's RSS (Rich Site Summary?) service
offers a quick way to check if a dataset on a remote ERDDAP™ has changed.
- ERDDAP's subscription service
is a more efficient (than RSS) approach:
it will immediately send an email
or contact a URL to each subscriber whenever the dataset is updated and the
update resulted in a change. It is efficient in that it happens ASAP and
there is no wasted effort (as with polling an RSS service).
Users can use other tools (like
IFTTT)
to react to the email notifications from the subscription system.
For example, a user could subscribe to a dataset on a remote ERDDAP™
and use IFTTT to react to the subscription email notifications and trigger
updating the local dataset.
- ERDDAP's flag system
provides a way for an ERDDAP™ administrator to tell a dataset on his/her ERDDAP
to reload ASAP. The URL form of a flag can easily be used in scripts.
The URL form of a flag can also be used as the action for a subscription.
- ERDDAP's "files" system
can offer access to the source files for a given dataset,
including an Apache-style directory listing of the files
(a "Web Accessible Folder") which has each file's download URL, last modified time, and size.
One downside of using the "files" system is that the source files may have
different variable names and different metadata than the dataset as it appears in ERDDAP.
If a remote ERDDAP™ dataset offers access to its source files,
that opens up the possibility of a poor-man's version of rsync:
it becomes easy for a local system to see which remote files have changed
and need to be downloaded. (See the
cacheFromUrl option
below which can make use of this.)
Although there are a huge number of variations to the problem and an infinite
number of possible solutions,
there are just a handful of basic approaches to solutions:
- Custom, Brute Force Solutions
An obvious solution is to handcraft a custom solution, which
is therefore optimized for a given situation: make a system
which detects/identifies which data has changed, and sends that information to the user
so the user can request the changed data. Well, you can do this, but there are disadvantages:
- Custom solutions are a lot of work.
- Custom solutions are usually so customized to a given dataset and given user's system
that they can't easily be reused.
- Custom solutions have to be built and maintained by you.
(That's never a good idea. It's always a good idea to avoid work and
get someone else to do the work!)
I discourage taking this approach because
it is almost always better to look for general solutions, built and maintained by
someone else, which can be easily reused in different situations.
- rsync (or similar)
rsync
is the existing, stunningly good, general purpose solution to keeping a
collection of files on a source computer in sync on a user's remote computer.
The way it works is:
- some event (e.g., an ERDDAP™ subscription system event) triggers running rsync,
(or, a cron job runs rsync at specific times everyday on the user's computer)
- which contacts rsync on the source computer,
- which calculates a series of hashes for chunks of each file and
transmits those hashes to the user's rsync,
- which compares that information
to the similar information for the user's copy of the files,
- which then requests the chunks of files which have changed.
Considering all that it does, rsync operates very
quickly (e.g., 10 seconds plus data transfer time) and very efficiently.
There are
variations of rsync
that optimize for different situations (e.g., by precalculating and caching the
hashes of the chunks of each source file).
The main weaknesses of rsync are: it takes some effort to set up (security issues);
there are some scaling issues;
and it isn't good for keeping NRT datasets really up-to-date (e.g., it's awkward
to use rsync more than about every 5 minutes).
If you can deal with the weaknesses, or if they don't affect your situation,
rsync is an excellent, general purpose solution
that anyone can use right now to solve many scenarios involving remote replication
of datasets.
There is an item on the ERDDAP™ To Do list to try to add support for rsync services to ERDDAP
(probably a pretty difficult task), so that any client can use rsync (or a variant)
to maintain an up-to-date copy of a dataset. If anyone wants to work on this,
please email erd.data at noaa.gov.
There are other programs which do more or less what rsync does, sometimes
oriented to dataset replication (although often at a file-copy level),
e.g., Unidata's IDD.
- The
cacheFromUrl setting
is available (starting with ERDDAP™ v2.0)
for all of ERDDAP's dataset types that make datasets from files (basically, all subclasses of
EDDGridFromFiles and
EDDTableFromFiles).
cacheFromUrl makes it trivial to automatically download and maintain the
local data files by copying them from a remote source via the cacheFromUrl setting.
The remote files can be in a Web Accessible Folder or a directory-like file list
offered by THREDDS, Hyrax, an S3 bucket, or ERDDAP's "files" system.
If the source of the remote files is a remote ERDDAP™ dataset that offers the
source files via the ERDDAP™
"files" system, then you can
subscribe
to the remote dataset, and use the
flag URL
for your local dataset as the action for the subscription.
Then, whenever the remote dataset changes, it will contact the flag URL for your
dataset, which will tell it to reload ASAP, which will detect and download
the changed remote data files. All of this happens very quickly (usually ~5 seconds plus
the time needed to download the changed files).
This approach works great if the source dataset changes are new files being
periodically added and when the existing files never change.
This approach doesn't work well if data is frequently appended to all (or most)
of the existing source data files, because then your local dataset is frequently downloading
the entire remote dataset. (This is where an rsync-like approach is needed.)
- ERDDAP's
ArchiveADataset
is a good solution when data is added to a dataset frequently, but older data is never changed.
Basically, an ERDDAP™ administrator can run ArchiveADataset
(perhaps in a script, perhaps run by cron) and specify a subset of a dataset
that they want to extract (perhaps in multiple files) and package in a .zip or .tgz file,
so that you can send the file to interested people or groups (e.g., NCEI for archiving)
or make it available for downloading.
For example, you could run ArchiveADataset everyday at 12:10 am and have it
make a .zip of all the data from 12:00 am the previous day until 12:00 am today.
(Or, do this weekly, monthly, or yearly, as needed.)
Because the packaged file is generated offline, there is no danger of a timeout
or too much data, as there would be for a standard ERDDAP™ request.
- ERDDAP's standard request system
is an alternative good solution when data is added to a dataset frequently,
but older data is never changed.
Basically, anyone can use standard requests to get data for a specific range of time.
For example, at 12:10 am everyday, you could make a request for all of the
data from a remote dataset from 12:00 am the previous day until 12:00 am today.
The limitation (compared to the ArchiveADataset approach) is the risk of a timeout
or there being too much data for a single file. You can avoid the limitation
by making more frequent requests for smaller time periods.
- EDDTableFromHttpGet
[This option doesn't yet exist, but seems possible to build in the near future.]
The new
EDDTableFromHttpGet dataset type in ERDDAP™ v2.0 makes it possible to envision
another solution. The underlying files maintained by this type of dataset
are essentially log files that record
changes to the dataset. It should be possible to build a system that maintains
a local dataset by periodically (or based on a trigger) requesting all of the
changes that have been made to the remote dataset since that last request.
That should be as efficient (or more) than rsync and would handle many difficult scenarios,
but would only work if the remote and local datasets are EDDTableFromHttpGet datasets.
If anyone wants to work on this, please contact erd.data at noaa.gov .
- Distributed Data
None of the solutions above does a great job of solving the hard variations of the problem
because replication of near real time (NRT) datasets is very hard,
partly because of all the possible scenarios.
There is a great solution: don't even try to replicate the data.
Instead, use the one authoritative source (one dataset on one ERDDAP),
maintained by the data provider (e.g., a regional office).
All users who want data from that dataset always get it from the source.
For example, browser-based apps get the data from a URL-based request,
so it shouldn't matter that the request is to the original source on a remote server
(not the same server that is hosting the ESM).
A lot of people have been advocating this Distributed Data approach for a long time
(e.g., Roy Mendelssohn for the last 20+ years).
ERDDAP's grid/federation model (the top 80% of this document) is based on this approach.
This solution is like a sword to a Gordian Knot — the entire problem goes away.
- This solution is stunningly simple.
- This solution is stunningly efficient since no work is done to keep a replicated
dataset(s) up-to-date.
- Users can get the latest data at any time (e.g., with a latency of only ~0.5 second).
- It scales pretty well and there are ways to improve scaling.
(See the discussion at the top 80% of this document.)
No, this isn't a solution for all possible situations, but it is a great solution
for the vast majority.
If there are problems/weaknesses with this solution in certain situations,
it is often worth working to solve those problems or living with those weaknesses
because of the stunning advantages of this solution.
If/when this solution is really unacceptable for a given situation,
e.g., when you really must have a local copy of the data,
then consider the other solutions discussed above.
While there is no single, simple solution which perfectly solves all the problems
in all scenarios (as rsync and Distributed Data almost are), hopefully there
are sufficient tools and options so that you can find an acceptable
solution for your particular situation.
The contents of this web page are Bob Simons personal opinions and
do not necessarily reflect any position of the
Government or the National Oceanic and Atmospheric Administration.
The calculations are simplistic, but I think the conclusions are correct.
Did I use faulty logic or make a mistake in my calculations? If so, the fault is mine alone.
Please send an email with the correction to
erd dot data at noaa dot gov.
Questions, comments, suggestions? Please send an email to
erd dot data at noaa dot gov
and include the ERDDAP™ URL directly related to your question or comment.
ERDDAP, Version 2.25_1
Disclaimers |
Privacy Policy
